Special Thanks to Pascal Dornier (from PCEngines)
http://www.pcengines.ch/
اینا رسیده و هفته بعد دو تا سیستم راه اندازی میشه با کمک دوست خوبمون جادی که لینوکس رو خیلی خوب میدانند.
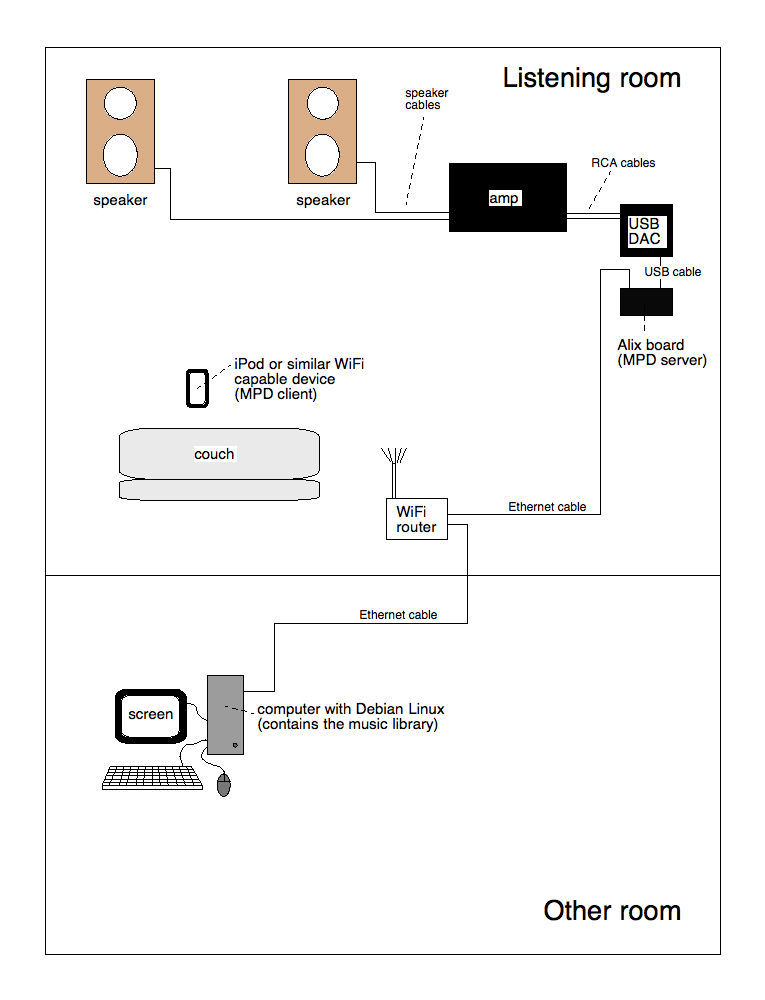
بعد از مک بوک من اومدم سراغ Alix و ممکنه بعدا سراغ BBB با RuneAudio لینوکس هم برم .
ببینید جمع بندی کامل من از همه مطالعاتم این شده کلا دو راه داریم.
یکی مسیر سرور کلاینت هست یعنی همین Alix هست با Linux Voyage MPD و یا BeagleBone Black با Linux RuneAudio که این حالت رو دارم تست میکنم همین هفته و نتیجه رو خبر میدم.
مسیر دیگه PC هست که حتما باید fanless باشه با هارد SSD متصل به mSATA . حالا یه سری میگن کم وات تر (زیر 10 وات) بهتره مثل Intel DN2800MTE Marshalltown یا Supermicro X11SBA-F با CPU Intel N3700 و یک سری هم میگن توان بالاتر بود مشکلی نیست مثل سری های 30 تا 80 وات Supermicro X11SSH-F Intel Xeon processor E3-1240 v5 یا Intel NUC DC53427HYE Core i5-3427U .
سیستم عامل برای PC هم عده ای معتقدند همین لینوکس Voyage MPD خیلی سبک خوبه و عده ای هم میگن ویندوز سرور 2012 و JPlay و استفاده از کد های Audiophile Optimizer .
بهتره CPU دو هسته یا 4 هسته باشه و برای CPU های کم وات و کواد کور سری های Core m3-7Y30 یا Atom یا Celeron یا Pentium N3700 یا N4200 که همه اینا زیر 7 وات هستند وجود دارند.
از کارت PCIe to USB JCAT Femto استفاده کنید. تو همه این حالات شما باید یه power Supply عالی داشته باشید یا حالا باتری عالی یا LPSU عالی و بدون اون نتیجه نداره.
http://www.thewelltemperedcomputer.com/Linux/Distro.htm
برای نصب نسخه 0.9.5 که بهترین نسخه هست :
https://www.hifi.ir/wp-content/uploads/2017/03/Voyage-MPD-0.9.x-Readme.pdf
http://zawiki.praxis-arbor.ch/doku.php/tschinz:linux_alix
http://cheap-silent-usb-linux-music-server.blogspot.com/
https://lacocina.nl/how-to-setup-a-bit-perfect-digital-audio-streaming-client-with-free-software-with-ltsp-and-mpd (این وبلاگ برای رونالد هست)
http://acquisitionsyndrome.com/2014/07/bit-perfect-liva/
برای کانفیگ بیت پرفکت mpd باید اینجا رو دانلود کنید :
https://github.com/ronalde/mpd-configure
Hi there,
All those new (and maybe even older) to music player daemon (mpd), linux and alsa, I’ve published a free script which with a single command generates a configuration file for mpd, which turns it in to an bit perfect music streamer.
The only requirement is that you have a working linux installation with mpd installed. After opening up a terminal screen, paste the following commands to generate and display a mpd configuration. When multiple audio cards (including USB DACs) are found, the script will ask you which one you want to use:
Code:
## make the directory where you want to download the script
mkdir /tmp/mpd-configure
## change to that directory
cd /tmp/mpd-configure
## download and unpack the script and other files needed
wget http://lacocina.nl/mpd-configure -O - | tar --strip-components=1 -zxf -
## run the script (the resulting configuration file will be displayed on the screen
bash mpd-configure
The script can be used in a fully automated fashion, by setting command line parameters and/or environment variables. In the following example, the result is saved to the system wide mpd configuration file `/etc/mpd.conf`, uses the first available USB Audio Class interface, sets the `music_directory` to `/srv/media/music` and the mpd ‘home’ directory (including its ‘database’) to `/var/lib/mpd`. In the case `/etc/mpd.conf` already exists, the script will make a backup of it:
Code:
## become root if neccessary
[[ $EUID -eq 0 ]] || sudo su
## set the paths to the music and mpd data directories and run the script,
## saving the output to `/etc/mpd.conf` while creating a backup of that file
## in case it exists:
CONF_MPD_MUSICDIR="/srv/media/music" CONF_MPD_HOMEDIR="/var/lib/mpd" \
bash ./mpd-configure --limit usb --noprompts --output "/etc/mpd.conf"
## restart mpd to use the new file
systemctl restart mpd
## done (press ENTER)
Some background information:
Regards and enjoy the music,
Ronald
این لینک هم شاید بدرد خورد برای نصب :
http://www.computeraudiophile.com/content/533-geek-speak-how-build-beaglebone-black-mpd-music-server/

اینم بخشی از نظرات همین آقای Ronald :
Hi,
Based on my personal listening experience, a highly overpowered fanless system, with a high quality linear power supply, fitted with voyage mpd or another “linux audio” system sounds best, although the quality of the digital source files seems even more important and troublesome because we depend solely on the mastering, packaging and delevering effort the supplier of digital music provided us with. In computer and software design we do have choice and influence.
The difference with “linux for audio” systems and what is called “optimized for audio” Windows or Mac systems is that the latter are “best effort reverse engineering efforts” at most, while the former can, could and should be truly “designed for audio”. The suppliers of the audio optimizers claim they made hundreds or even a thousand of registry tweaks, but don’t mention the tens of thousands system properties they aren’t aware of or simply can’t access.
I’m an IT guy, and as such, don’t like perhaps and maybe when it comes to software design and implementation. On the other hand I’m a music lover, where emotion, personal interpretation and feeling are core values which I cherish and love. In these kind of discussions I get a bit annoyed by the fact that the domains of software, electronics and music get mixed up altogether.
Audio enthusiasts tend to use the same vocabulary for describing IT-systems and electronics. But they arent’t comparable. On the other hand, none of those guys and girls, who take their audio serious and are open minded at the same time, have ever looked for a “best effort reverse engineered” amplifier. When it comes to audio electronics, they go for the greatest design, coupled to a flawless, albeit affordable, implementation. The CAPS proposal is, as far as its hardware properties goes, exactly that.
The CAPS software properties on the other hand experience precisely the problem I described. “Audio Optimizers” for Windows or Mac do exactly what they preach, but we shouldn’t want that, nor do we need that. We should demand “designed for audio” software and are lucky enough to have such a system at hand, or at least something we could get to work that way. Because it is long standing, much debated, completely transparent and actively maintained, we can and should aim for perfect. Nothing less. We don’t have to reverse engineer it, modify 1.000 of its 40.000 registry settings. We can simply design it to work the way we want it to.
Good luck choosing your hardware! Run a designed for audio Linux together with mpd* —of course in bit perfect mode— and you’re ready to challenge the best analog setups, as long as your digital source files are made with love.
Regards,
Ronald
I started out with a diskless client (OS and software both run from the network) while the music resides on a NFS server. The first one was designed around an HP t5725 with an AMD Geode NX 15002 dual core) around 2005. I than stepped up to a Intel DN2800MT dual core Atom board, with which I was happy.
Until I heart my new Intel Core i5-3427U ULV NUC board, which I initially bought for playing back video (using xbmc). For playing back two channel digital audio (even at highest resolutions) it is overspecced by far, but it just sounds better.That is a result of the packing of the SPDIF frames inside USB URBs, which suffers from resources under load by design. To really fix that issue, we need a new discrete/i2s-like (open) standard.
As you can see in the changelogs of both the article and the script, that stuff is very recent. Of course Windows and Mac made progress the last years, as did Linux (and its alsa sound system, its UAC kernel modules/drivers and the music playing software mpd). But load on the system and its resources still have a negative impact on sound quality while maintaining stability and quality over longer periods of time takes up a lot of effort. So even today, those things need to be “managed” by reverse engineering on closed platforms.
Regards,
Ronald
لینک های رونالد :
https://github.com/ronalde/mpd-configure
https://lacocina.nl/bitperfect-audio
https://lacocina.nl/audiophile-mpd
https://lacocina.nl/how-to-setup-a-bit-perfect-digital-audio-streaming-client-with-free-software-with-ltsp-and-mpd
https://lacocina.nl/detect-alsa-output-capabilities
https://lacocina.nl/disable-pulseaudio
اینم یه بخش دیگه:
A dedicated designed-for-audio computer (hardware part)
On the hardware side we’re looking for a fanless, diskless and headless industrial grade PC with two CPU cores and two network interfaces.Fanless: We aim to minimize noise and vibration.
Diskless: We don’t want spinning disks inside our box, because they cause noise, vibrations and power fluctations. The only disk inside the PC will be a small mSATA solid state disk, to store the OS and music playing software on. Those wille be loaded in memory at power up, after which everything is booted and executed from RAM. We will be storing user files, like audio files, settings and preferences, on a network storage device. This way, we’ll complete eliminate activity on the SATA-bus and controller.
Headless: We only want the PCIe/USB-busses and controllers be dealing with the handling of audio. So there will be now screens or input devices attached to our box and we have no need for resource hungry 2D/3D graphics systems and their complex and error prone drivers. Instead we’ll be controlling the OS and music playing software from native applications on other devices, like desktops, laptops, smartphones or tablets, or, if desired, with any webbrowser on the local network using a webserver on the music playing PC. Of course, that would require careful implementation and resource assignement, as we would want to minimize it’s influence on audio related processes.
Industrial grade We’re looking for a system that lasts at least ten years with extensive use, without active cooling and with minimum EMI/RF radiation and vibration. We want extended lifespan components from well established suppliers. We want a well build non-vented box with as few holes as possible. We only need holes for connectors, two for ethernet, two for usb and one for power.
Two CPU cores We want a dedicated core to which we will tie all processes related to audio with realtime priority. Here processess will run like audio file retrieval from the network including the network stack itself, the usb stack and the processes needed for the music playback software. All other processes, like logging, controlling and the optional webserver, will be tied to the second core.
Two network interfaces We want a single dedicated gigabit network adapter with hardware TCP/IP offloading for retrieval of audio files on the network. All other network traffic, like control sequences, will be redirected tot the second (built-in) network interface.While the C.A.P.S. proposals are great, things can be simpler, cheaper and even better.When your on a tight budget (aren’t we all?) buy yourself a fanless industrial Intel dual core Atom based based system, like the Logic Supply AG150, configured with 2GB RAM, an idustrial 32GB msSATA drive and a best-in-class Seasonic switching power supply for around $390/€260, and you have a great starting point for this purpose.More speed means less switching, so if you can afford it, you might want to spend around double that money and buy a fanless industrial Intel dual core i5 Haswell based system, like the Logic Supply ML320, configured with 4GB RAM, a 32GB internal mSATA drive and a best-in-class Seasonic switching power supply for ~$750/€560. This system features the-best-in class NUC-design, coupling the CPU directly, so without heatsinks, to the upper side of the box. The upper part of the box is a folded sandwich construction of thick aluminium and thinner iron, which is great because it not only keeps the cores cool but minimizes RF/EMI radiation and vibration as well.You might improve on the rather good basics by replacing the switched mode adapter with a proper linear audio supply. I still haven’t come around to listen to the effect of such an upgrade, and I’am currently working with a local engineer to get such a beast built.The use of a dedicated USB PCIe card designed for audio in the PC, like the ones offered by Sotm (~$300/€350) or Paul Pang / PPA Studio (~$130) (who also offers great audio PC’s and other tweaks) did do some good in the Atom based system, but did not have any audible effect in my Core i5 system. This probably is due to the fact that I didn’t use an external linear power supply to feed the cards.
Other tweaks, like dedicated audiophile SATA-controllers and cables, do not apply to our system, as we only use our solid state mSATA disk to boot the OS and music playing software. After that everything will be executed from RAM, thereby bypassing the SATA-bus and controllers completely.
A dedicated designed-for-audio computer (software part)
As Microsoft has a long and bad track record of proprietary, hidden and non-sustainable “standards” and technology while frustrating open standards, they are not the supplier I want to attach myself to. But there are those who do and some of them have created some nice offerings, which can be divided in two categories.The first type consists of stuff that’s meant to be used like a desktop, connected to a TV and input devices or touchscreen, like JRiver Media Center (~$50/€40) and the free (as in free beer) closed source and proprietary Foobar. Of course that price is without a valid Windows (desktop) license, which those users –knowingly of course– bought as part of an OEM-installation for about $100/€100. For reasons described in this article, I don’t like all-in-one solutions like these and I’m not interested in them.The headless ones (based on Windows Server) are –as designs– more to my taste, like Audiophile Optimizer (~$100/€80) and JPlay (~$130/€100). Apart from that, you will of course need to buy a proper Windows Server license, which is an art in its own, that will set you back more than $300/€300 (just an estimation).Apart from the price, the Windows based “products” all suffer from two intrinsic problems. The first one is that Windows seized supporting USB Audio after Class 1 was defined, back in 2006. A a result, there’s no native UAC2 support in Windows, which means you have to revert to third party (and closed source) drivers, which is something I’m surely not after. The other problem is that they can only go forward by going backwards, ie. by reverse engineering. Thereby they’re battling their supplier of choice, which seems silly in my opinion. Generally these “products” consists of registry tweaks and scripts that disable standard services or tweak the system in some way. Their developers bet they can get and keep the OS, drivers and software in control that way, and hopefully the 25.000 remaning settings, proprietary drivers and their updates don’t interfere with their plans. The same applies to Apple, although the underlying OS does offer more possibilities.
On the other hand, using free and open source software one can design and build a custom dedicated OS with playback software for a single purpose; getting the AES/EBU signal from the files on the network to your external UAC2 DAC in the best possible way.
Some of my fellow enthusiasts have created some great things based on free and open software. AudioPhile Linux is in active development and uses Arch, which is fitted with a custom realtime kernel and mpd. Voyage MPD, the first audio oriented system in a single compressed image, together with Vortexbox are geared towards small and cheap embedded DiY platforms, like Beaglebone and RaspberryPi.
Mine consists of a fully automated silent installation of a heavily customized (not reverse engineered) Debian with a custom compiled kernel based of the stock backported realtime kernel. It uses stock mpd and alsa modules and libraries and achieves great results.
Read More